This is the latest in a series of blog posts to address the list of '52 Things Every PhD Student Should Know' to do Cryptography: a set of questions compiled to give PhD candidates a sense of what they should know by the end of their first year. We continue the Mathematical Background section by introducing the Elliptic Curve Group Law...
The Elliptic Curve group law is a method by which a binary operation is defined on the set of rational points of an elliptic curve to form a group. Now, lets go through what that actually means, and what it's used for. Thanks to Dr Dan Page for providing the group law diagram.
An Elliptic Curve and its rational points
An Elliptic Curve is a cubic equation in two variables over some mathematical field. They can be written in various forms, but over most fields 1 can be written in short Weierstrass form:
$$E : y^2 = x^3 + ax + b $$
For now we will assume that we are working in the field of real numbers, and ignore any complications that come from using finite fields. With some simple requirements on $a,b$ (specifically, that $27b^2\neq -4a^3$) this is an elliptic curve.
The set of points that will be elements of our group are going to be the rational points of the elliptic curve. This is simply the collection of points $(x,y)$ that satisfy the curve equation where both $x,y$ are rational. So, that's the set of $(x,y)\in \mathbb{Q}$ where $y^2=x^3+x+b$. For reasons that will become clear, we also include a point at infinity 2.
Adding a Group Law to an elliptic curve
The simplest way to describe the relation we're going to add to the set of rational points is with a diagram:
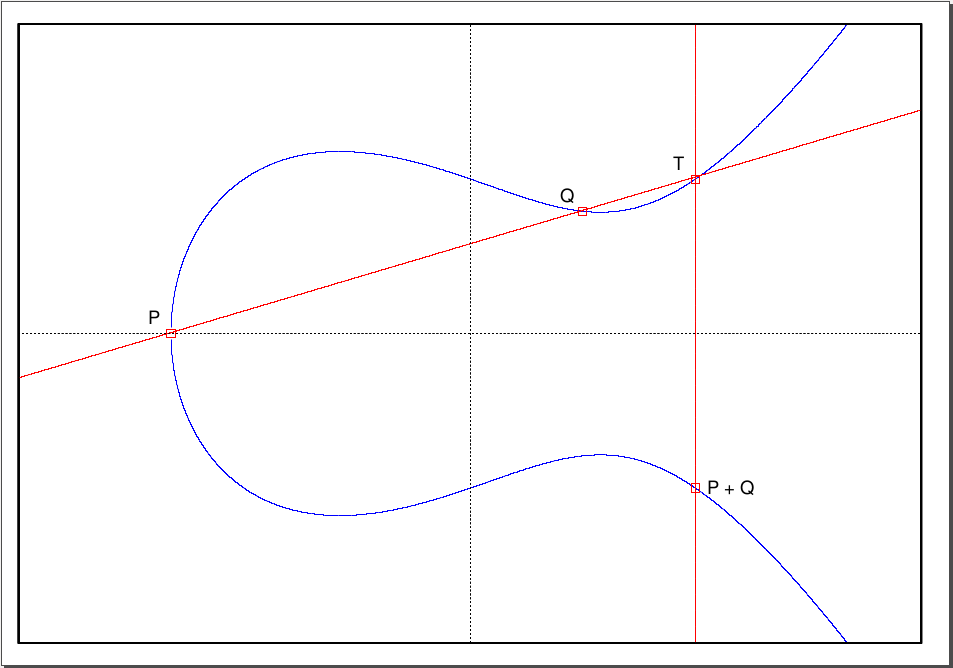 |
| Elliptic Curve (blue) with two points (P,Q) and their sum (P+Q) plotted, along with construction lines (red) |
So, to add together $P$ and $Q$, we draw a line through $P$ and $Q$, and make $T=(T_x,T_y)$ the third point this line intersects the curve. Then, $P+Q=(T_x,-T_y)$. To add a point to itself, we take the tangent at that point. Now, the surprising fact is that this operation defines a group, with the point at infinity the neutral element.
Most of the requirements of being a group are easy to see geometrically3. For example, it is easy to find the inverse of an element. In the diagram above $(P+Q)+T=0$, because the line from $T$ to $(P+Q)$ has it's third intersection at infinity, and so $(P+Q)=-T$. In fact, for any elliptic curve in short Weierstrass form, to negate a point we simply change the sign of it's y-coordinate.
Is that all there is to it?
Pretty much yes. The same method holds to over finite fields, although in this case it tends to be simpler to think of the group's operation as being an algebraic construct rather than geometrical, since Elliptic Curves over finite fields do not have such an intuitive structure. Also, we don't need to view curves in short Weierstrass form, since there are many different coordinate schemes and equations that represent the same curve. Indeed, some choices of curve and coordinate system assist us in doing certain types of computation.
What's that got to do with Cryptography?
It turns out that over certain finite fields the Elliptic Curve Group has several nice properties for cryptographers. There are a surprisingly large number of curve and field pairs where it's not too costly to do group computations4, but for which the various discrete log or DH problems (see last week's blog) are hard. Moreover, compared to using large multiplicative groups (eg RSA groups) the variables computed with are much smaller. Putting all these together, elliptic curves allow cryptographers to efficiently calculate ciphertexts that are much smaller than those created by alternative means without reducing security.
- Specifically, fields of characteristic not equal to 2,3. That is, fields where $2\neq0$ and $3\neq 0$. Unfortunately, this obviously means that the results we discuss won't hold in binary fields, but that is rather beyond the scope of this talk.
- Justification for this comes from considering the elliptic curve as a curve in projective space, but for now it suffices that such a point exists.
- Associativity is by far the most complicated to show. This diagram on wikipedia explains the concept behind the proof, although the details are rather involved.
- Even as I write this, I'm sure someone will question the validity of this claim, but it is true that compared to many groups that one could construct in which the required problems are sufficiently hard, point arithmetic on an elliptic curve is comparatively tractable.